News & Updates: Data in Practice: Attorneys’ Fees and Data
Data in Practice: Attorneys’ Fees and Data
Posted by Marie Jonas
One of the most common practical applications of basic data analysis in litigation is with attorneys’ fees. Understanding, challenging, or defending them.
Case Context
Consider this. A few months ago, the ABA Journal covered this case from the Federal Circuit, reversing a fee award of $185 million (5% of the settlement value) in a class action because the trial judge did not conduct a “lodestar cross-check” that considered the hours worked by the trial counsel in obtaining an over $3 billion settlement. Of course, most attorneys will never work with fee figures quite that large, but often are faced with quandaries about how to defend – or attack as unreasonable – attorneys’ fees in any number of settings.
As explained in the Manual of Complex Litigation (§ 14.122), many quantitative factors go into the reasonableness assessment of fee awards in class contexts. In other contexts, as well. But as often as not, attorneys work with only the highest-level totals from accounting software in analyzing their own, or an opposing party’s, fees. With only high-level aggregates, attorneys miss key insights about where time is spent, and how to construct a compelling narrative behind it. But with a basic grasp of Excel, attorneys can much more efficiently dissect and understand where attorney time is going, to be prepared to back it up, add more detail, or run functions to cross-check against other awards or data. All that, without needing to invest in new, complex, reporting software.
Basic quantitative analysis is unlikely to help justify an implicit multiplier of 18, but as we’ll go through in upcoming posts, it can help streamline your fee analysis in multiple settings.
Building Your Data Set
Remember, a few weeks ago, we worked with a data set of time entries. Often, the default information that’s included in such a data set is simply: date, timekeeper, time, rate, and narrative. When you think about how to set up a data set to analyze it, think about what information you might want to aggregate and compare. From there, you can populate your own fields (new columns) as you go through and review an underlying set of information.
Category: Sometimes category fields are already included in standard attorney time entries. It makes sense. A higher-level categorization for attorney time (grouping like entries together), will enable a quick sense of how long has been spent on particular activities: like drafting, client comms, or analysis. If they aren’t tracked with underlying time entries, it might make sense to apply categories to such a data set in order to track groups that are meaningful to analyze.
I often use a filter to categorize quickly. If there is a word in a narrative field that matches a specific category, I can narrow the list, and cut and paste a category into the applicable cells.
You can look up “complaint” to track a new category of “Drafting”.
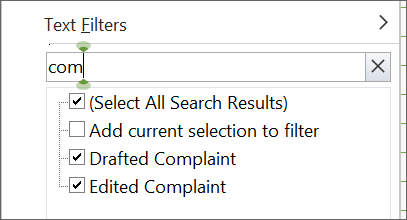
Or maybe all that document review, you’d like to categorize as “Analysis”.

This can help make it easy to apply categories to your set of time entries.
Notes: I often caution people about using notes fields, because they can be very difficult to systematically track and analyze in a data set. Frequently, they’re prepared on an ad-hoc basis, without much thought to application. But a notes field used during a linear review of something like attorney time can be immensely helpful, particularly when you plan ahead to track specific issues in a systematic fashion. For example, in this data set:
- We might filter for identical time entries to find material that might be duplicative.

- We might target particularly long entries to review for length.

- Perhaps certain entries just look…off. You can use a thoughtful notes field to track something like “Follow-up”.
As we’ve gone over before, building a “clean” data set, with all the information you are interested in tracking, is the critical first step for further analysis. Next week, we will dive into some further pivot tables, focusing on attorney time.
Sheet Cheat
The Sheet Cheat will feature a short excel function or data tool for readers to try out. Please share your favorite cheat via email, and I may include it in a future post!If you are using a field like “category,” you might want to limit what someone enters into cells in that column. Here are a couple quick tricks to ensure that you are using clean and consistent data when populating a new field.
Unique: Let’s say there’s already information in some of the cells in your field, and you want to extract just the unique entries (similar to what you might see when you click on the filter in a column header). You can set up a “unique” function to list just the unique entries in a given range.
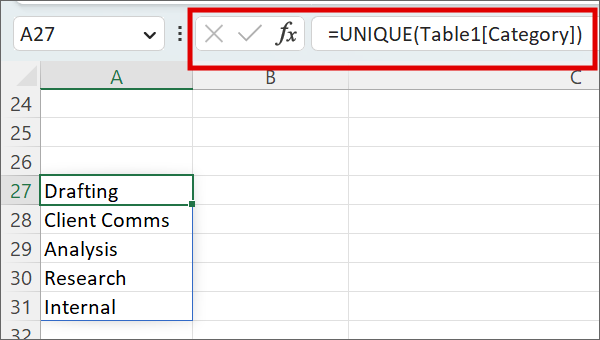
Here, the “Table1[Category]” syntax refers to the “Category” column (“[Category]”) of the data set that I have formatted as a table (“Table1”).
You can also write this as a standard range: =UNIQUE(G2:G22), where “G2:G22” refers to column G, rows 2-22, where my Category column lives.
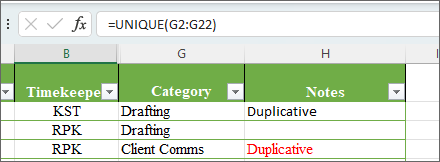
This function spills over into surrounding cells, and data in the cells below where the function is entered with show a greyed out function in the function bar:
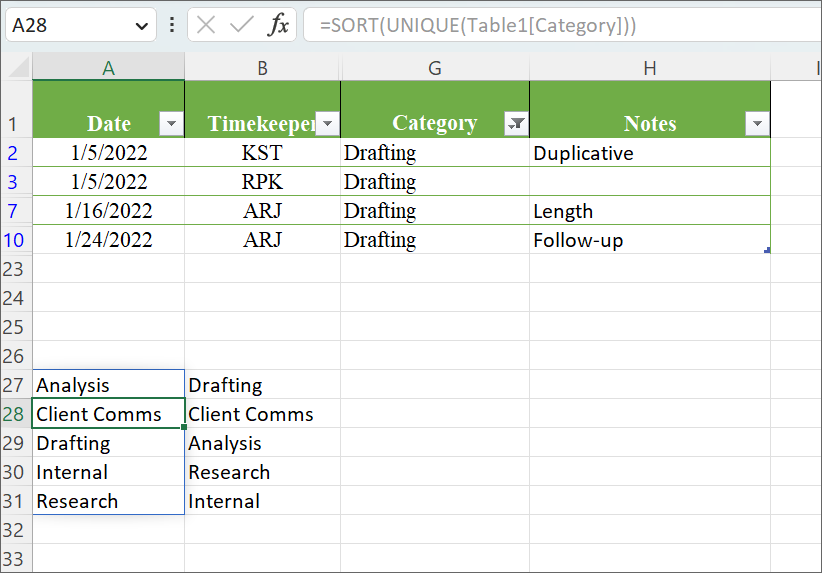
You’ll see here, I used the “Sort” function before “Unique” to alphabetize my categories.
Data Validation: If you want to make sure that someone only populates cells with discrete items from a list, you can use data validation. To set up data validation, first select the cells that you want to restrict (here, we will select Column G, “Category”). Navigate to “Data” on your ribbon, and select “Data Validation,” then “Allow:” a “List” – listing in the “Source:” the location for the list of options that you want to appear.
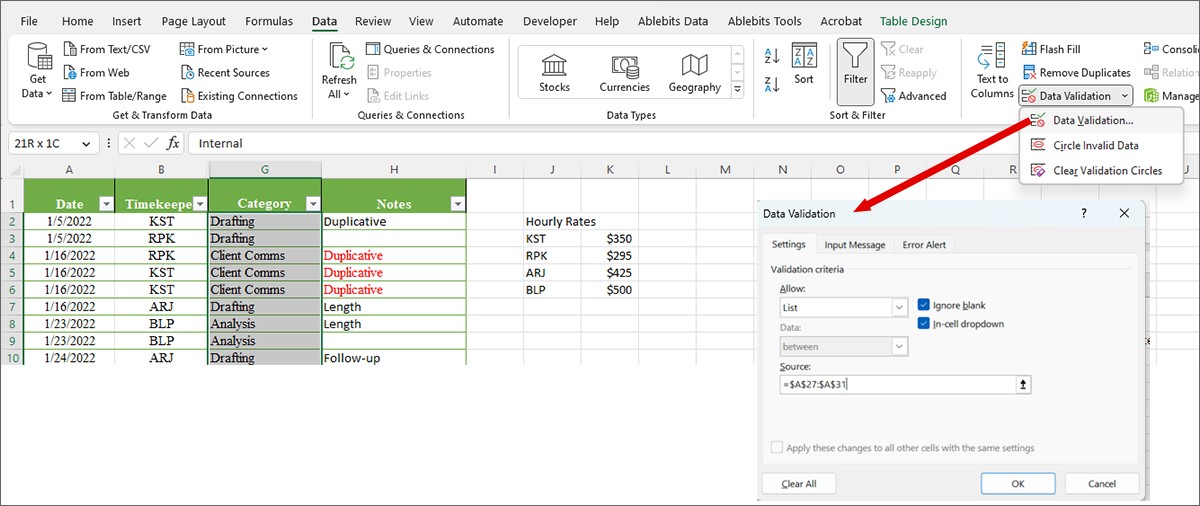
Now, in any blank cell in the range for which you set data validation, you will get a drop-down menu of just the options on your list:
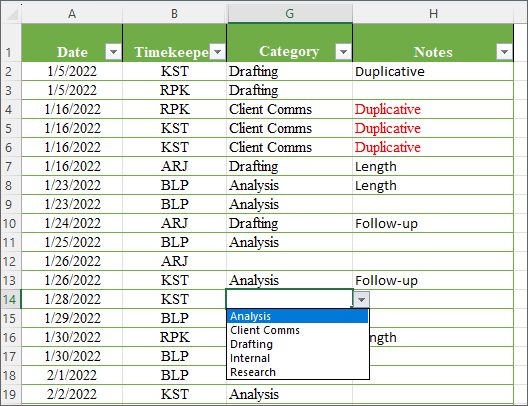
You’re now set up to make sure your data entries are clean and consistent.
Data permeates every aspect of legal practice. Data in Practice is a bimonthly feature to provide practical tools for attorneys to better organize, manipulate, and understand data. Whether it’s working with basic case information, preparing document productions, or conducting exposure analyses, a more robust knowledge of Excel is guaranteed to streamline your work. A few simple tools can help attorneys more efficiently and effectively represent their clients, and better navigate a professional landscape inundated with big data.
Marie Jonas is a Partner in Folger Levin’s litigation practice group. Marie has over a decade of hands-on experience working with Excel in all aspects of her practice: ranging from investigations to trial. If you have an idea for a topic involving practical data tips for lawyers, she can be reached at mjonas@folgerlevin.com.