News & Updates: Data in Practice: Data Clean Up
Data in Practice: Data Clean Up
Posted by Marie Jonas
Fix it First
Best to cut to the chase! Before you are able to get the most out of Excel, you need to make sure to put the best in. That means, whatever data set you are working with, you need to make sure it is: (1) accurate, (2) complete, and (3) properly formatted. If you give the program bad information, it is going to give you incorrect conclusions. As the saying goes: garbage in; garbage out. Because of that, the first step I take with any data set I work with is data clean up with a quality control process. This step is often the most tedious, the most time consuming, and the most important.
(Remember, sample data can be accessed here)
The QC Process
Here is a quick run through for doing a quality control check on your initial “raw” data set (the granular information that is not summarized or aggregated). Once the raw data is tip-top, then Pivot Tables and other tools will fall into place.
Accurate
If you receive a set of data, it’s helpful to do an initial gut check on what you are looking at. Some questions to ask when assessing information include:
⚬ Is the volume of information in line with what you were expecting?
⚬ Do you see any obvious aberrations (such as dates outside of an expected range, or figures in excess of what is plausible?)
⚬ Are the fields (columns) included in the data set descriptive and inclusive of what was needed or anticipated?
If there is some core inaccuracy, or piece of information missing, any summary functions will lead to faulty results. And, you are likely to waste time cleaning up and manipulating data that won’t give you useful information.
NOTE: A key benefit of summary tools like Pivot Tables does include checking for inaccurate information in the underlying data. We’ll get there in coming weeks.
Complete
If you are happy with the general look of the data, the next clean-up step involves making sure the information is complete. I don’t mean, “does the universe of data include all the entries expected,” rather, the question is, “does each unique entry include all relevant information.” A “unique entry” for these purposes is one row of data
Lawyers are used to working with and presenting data in summary format, without regard to the underlying raw or granular data. For example, they might receive summaries of attorneys’ fees or expenses that look like this:
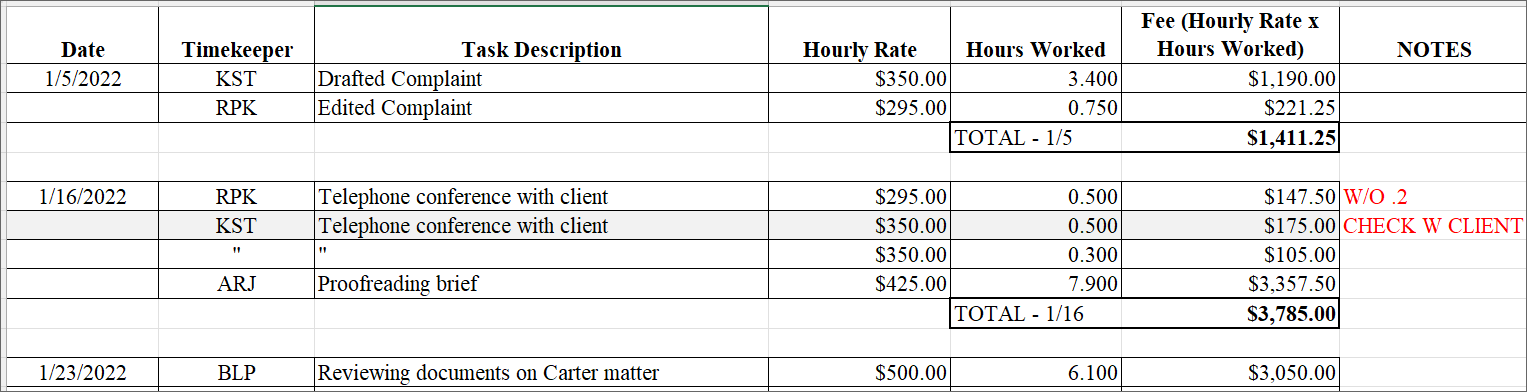
While the formatting here might be useful or appropriate for transmitting a report on the underlying information, certain aspects of this table make the raw data incomplete for our purposes: running further analysis on the underlying information.
First, you’ll note that, rather than including a date in every row, the data is meant to be read in summary fashion – assuming the reader understands all information below the top line occurred on the same date. While you might understand that, Excel doesn’t. For a raw data set that you’ll summarize later, make sure all relevant information is included in every row.
NOTE: To quickly populate data, try these shortcut keys:
⚬ Ctrl+D: Copies information from the cell above.
⚬ Ctrl+Shift+[Directional arrow]: Selects information to the next populated/empty cell. (Use Ctrl OR Shift+[Directional arrow] to navigate to a cell or select the next cell, respectively.)
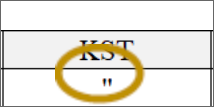
Second, you’ll see that the references to one piece of information, here – an attorney’s initials – is inconsistent. Instead of KST on every like, a shortcut was used.
Excel isn’t going to know what this symbol references. Make sure that all “like” things are described the same (so that they can be grouped together later). This includes making sure that there are no typos or extra spaces in cells, which will throw off your summaries.
A quick way to check if the data is off? Once it’s filtered, check out the contents by clicking on the down arrow in the bottom right:
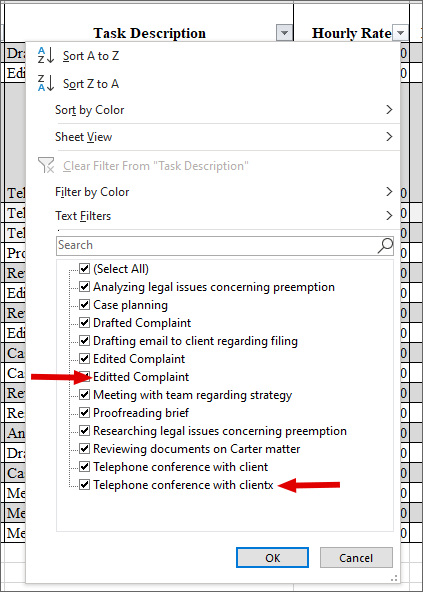
Here, the narrative typos jump out at you…so you can select and fix them.
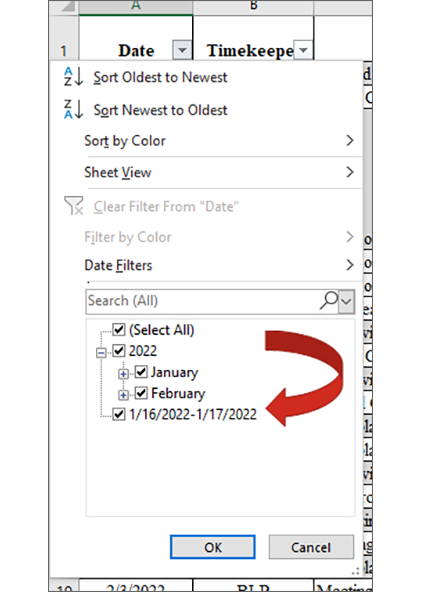
And here, it is easy to see which entry is not in a proper date format…if there is a date range, make sure to set up two columns – one for a start date, one for an end date.
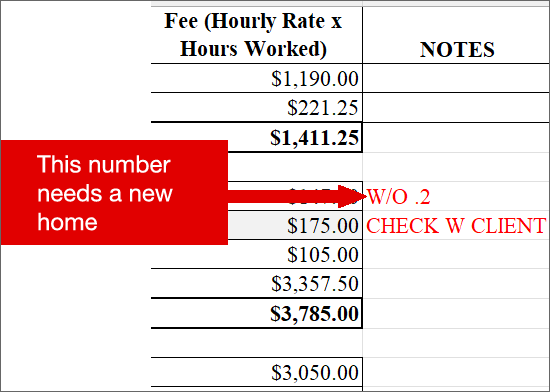
Finally, our data set seems to be missing a field: the “Notes” column refers to critical data (a write-off of hours) that might need to be included as a modifier to another field (total hours). But that information doesn’t have a useful home, because the “Notes” column includes various miscellaneous information and cannot easily be formatted as a number.
Rather than have this critical information living in the notes, a more efficient way to work with the data will be to have a separate column to capture this information – for example, an “adjustments” field.
Making those changes, we’ve now progressed to a more complete data set that will be easier to work with down the line.
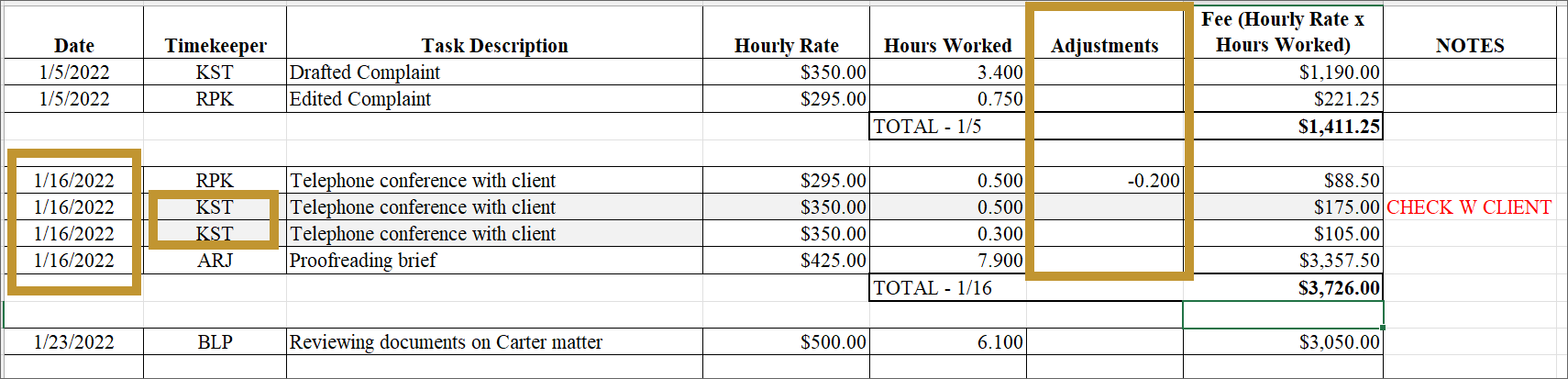
Here we added dates, filled in our timekeepers, and included a field for time adjustments.
Properly Formatted Structure
One final initial note on cleaning up data involves more structural formatting. In the data sets we worked with in prior posts, the information was already arranged with one line of data on each row, composing a complete table. Here, there is summary information in the middle of our table, and blank spaces abound.
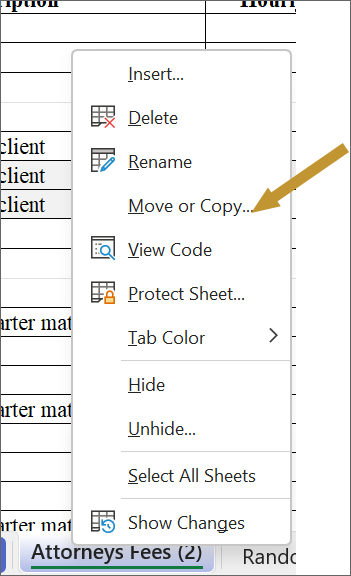
NOTE: Summary information like that displayed in the initial table can be very useful to preserve. Remember, just right click on the name of the sheet on the bottom of the screen, and click “Move or Copy…” to rapidly duplicate a sheet. Save the summary while you tweak or build out the raw data.
In order to make our raw data more usable, we want to take out blank space and interim summaries like those highlighted below:
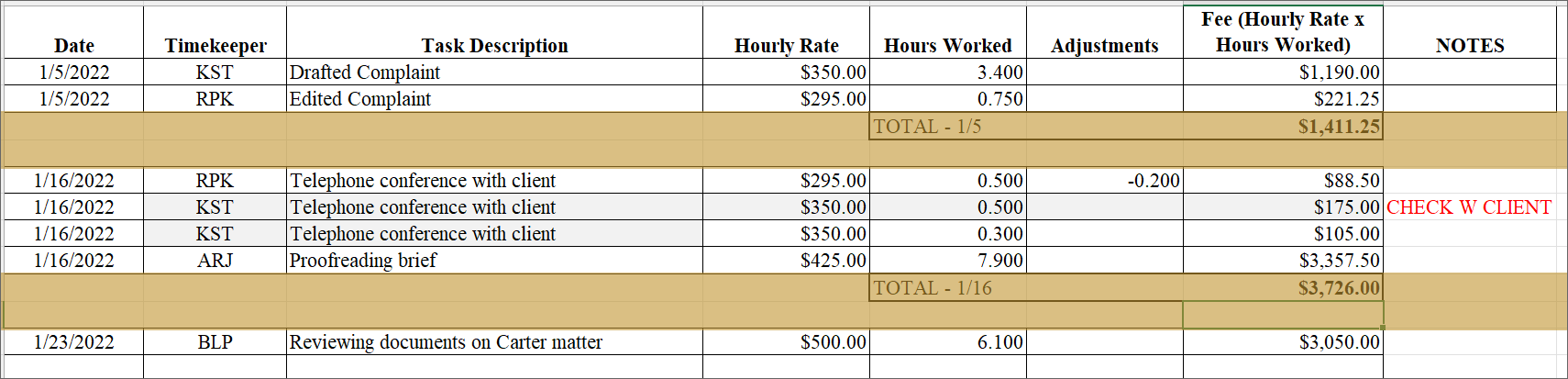
We can run more complete – and nimble – summaries later, once our data set is complete. Select the information you want to remove, right click, and navigate to Delete. Make the appropriate selection. Typically, in data sets like this, you’ll want to “Shift cells up” or delete the “Entire Row.”
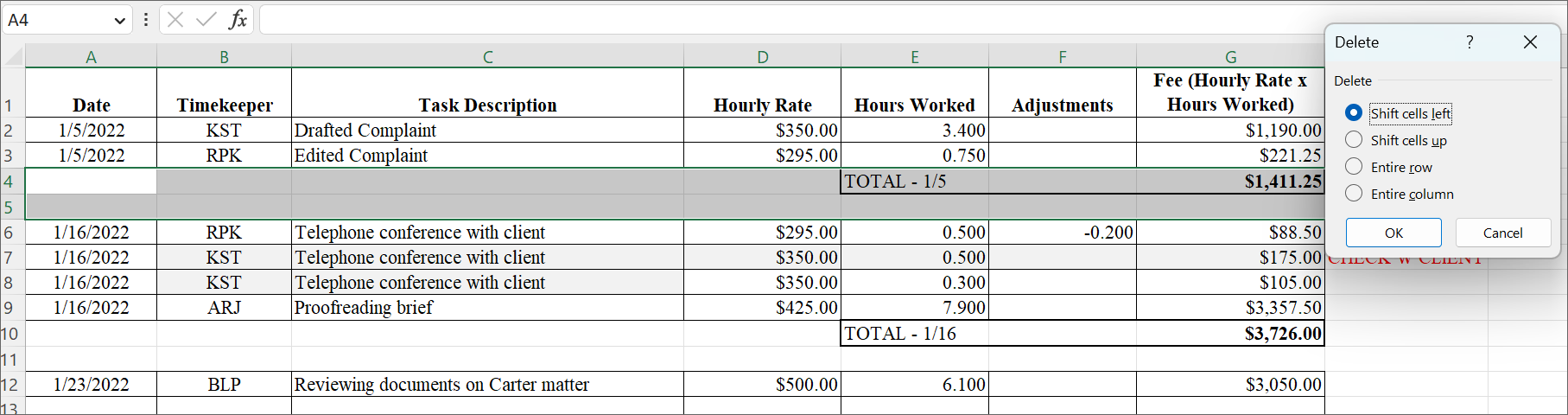
Et voila! Updated data that is ready to be formatted as a table, and summarized using Pivot Tables – to be covered in the next post.
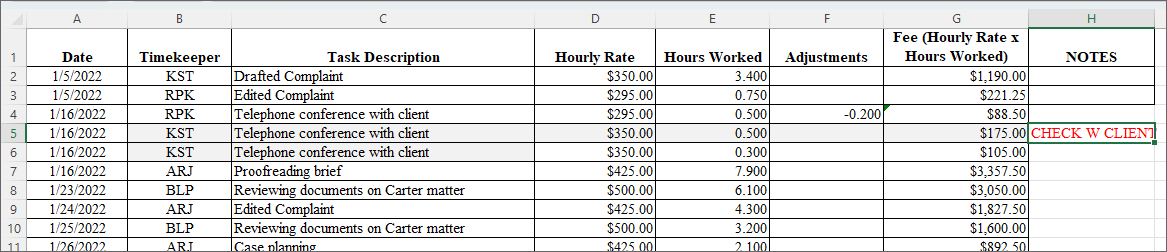
It may seem basic, but cleaning up raw data is critical groundwork for any further analysis you may want to conduct.
Sheet Cheat
The Sheet Cheat will feature a short excel function or data tool for readers to try out. Please share your favorite cheat via email, and I may include it in a future post!Let’s take a moment to preview another helpful function that many are not familiar with: simple concatenation. Concatenation just means linking things together in a row. Consider the table above: let’s say you want to form a line of text (a “text string”) that lists out all of the task descriptions consecutively in your notes column. Easy.
Assuming the text you want is in cells C4, C3, and C2, you can write in a new destination cell: =C4&” “&C3&” “&C2.
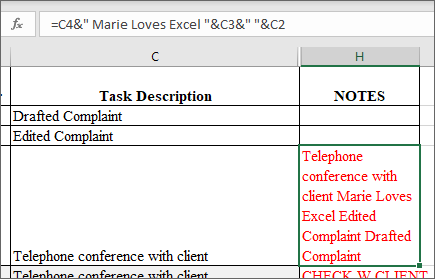
This tells Excel to pull the contents of those three cells, and combine them into one cell, with spaces in between. If you want to add text, simply type it where the space is listed, between the ampersands, as shown here.
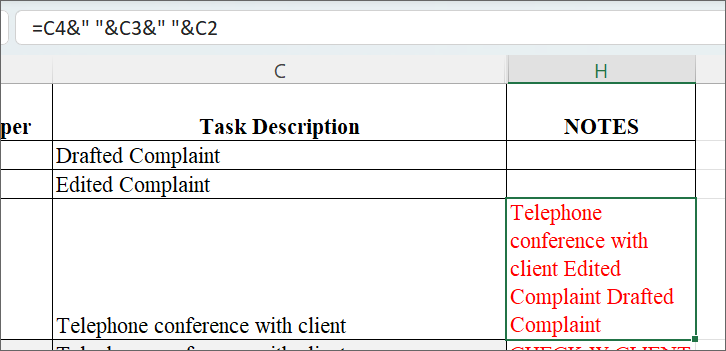
If you want to add text, simply type it where the space is listed, between the ampersands, as shown here.
Data permeates every aspect of legal practice. Data in Practice is a bimonthly feature to provide practical tools for attorneys to better organize, manipulate, and understand data. Whether it’s working with basic case information, preparing document productions, or conducting exposure analyses, a more robust knowledge of Excel is guaranteed to streamline your work. A few simple tools can help attorneys more efficiently and effectively represent their clients, and better navigate a professional landscape inundated with big data.
Marie Jonas is a Partner in Folger Levin’s litigation practice group. Marie has over a decade of hands-on experience working with Excel in all aspects of her practice: ranging from investigations to trial. If you have an idea for a topic involving practical data tips for lawyers, she can be reached at mjonas@folgerlevin.com.